
人工智能如何助力企业突围互联网运营困局?
2019-02-15

意见
反馈

回到
顶部

Joshua Litven,James Lee & Oamar Gianan 2018-04-26
想必你一定很喜欢这样的场景:和三五好友一起,踏着音乐的节奏,一起开车出游。但很久以来,一直有一个不成文的规定:谁开车谁就掌握了决定听什么歌的权利。其实这很容易变的无趣,尤其当开车这位的品味奇差的时候,你会看到人们纷纷戴上耳机听起自己的音乐,并因此而减少了和其他人的互动。所以,关键是要有一个符合所有人品味的歌单。
在这个项目中,我们就试图挑战这样的任务:为拥有不同品味和偏好的多位用户创建一个能带来一致的绝佳听觉体验的歌单。我们为此制作的基于Flask的app叫做Orpheus。它使用了Spotify提供的接口。
我们从Echo Nest收集了用户品味的相关数据。我们使用这些数据来训练单个用户的推荐系统,之后使用Apache的Spark机器学习算法库来进行协同过滤,从而搭建一个潜在因子模型(latent factor model)。这个模型之后会用于一个集合策略,来决定多个用户的喜好并据此推荐歌单。最终这个歌单会发送到app上,供用户使用。
具体流程图如下:

我们爬取的数据包括1,019,318个独立用户,384,546首歌曲和48,375,586个独立的对用户-歌曲-播放量三个数据的综合分析。数据一共占了5GB。
有了用户的收听记录数据,接下来可以建设推荐系统。两种主要的方式是:基于内容的过滤和协同过滤。
我们选择了协同过滤的隐语义模型的方式,因为它在处理比较隐藏属性强的反馈时能力突出,而且可扩展性突出。另外Spark还有ALS的设置。
这个模型从用户与产品之间的隐含关系出发来做推荐。具体来说,给定一个用户评分矩阵,这个模型会找到如下所示的低阶矩阵。用户和一个物品的潜在影响因子(latent feature)的点积(dot product)代表用户的预测评分。对所有物品的预测评分会进行计算,按最高预测评分给出推荐。
低阶矩阵由解答下面的最优化问题来解决。
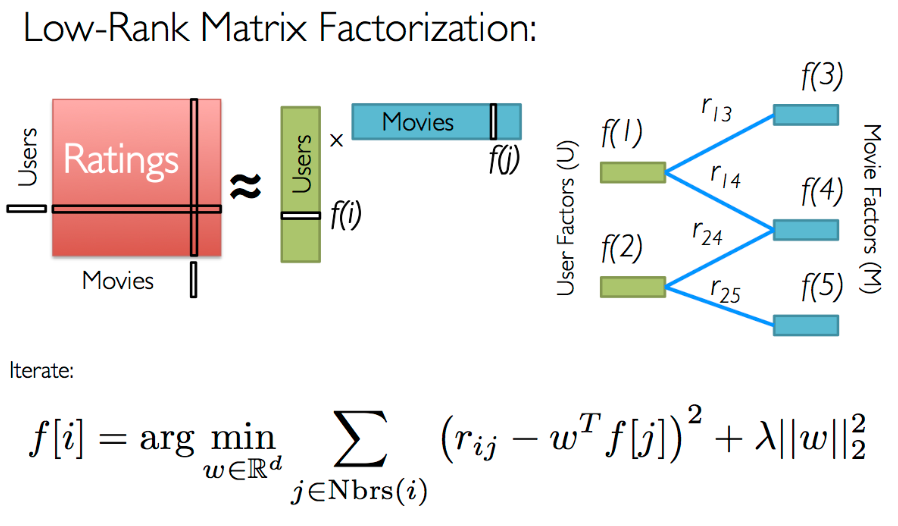
隐含的模型工作原理略有不同。它没有尝试预测明确的评分,而是用这个函数给了一个用户u会喜欢物品i的置信值:

α是模型的调整参数。最优化的问题就变成了:
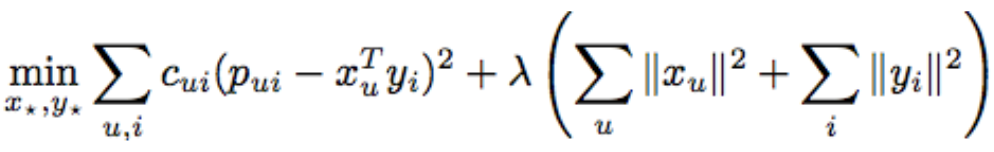
这里p_ui代表用户是否喜欢这个物品,c_ui代表我们对于他们喜欢这个物品的置信度。
矩阵的质量是评估推荐系统的常用办法。简单说,它可以让我们基于它们对预测物品的评价来评估质量。为了评估我们的模型,我们使用了MAP——平均精度均值。
拿到一个用户的听歌历史和推荐结果P(precision-at-k),即返回的top k个结果中的精度,衡量了top k个推荐中正确推荐的比例。平均精度(AP)是在每个召回点(recall point)k的精度,平均精度(MAP)是所有用户的AP的平均值。
为了评估模型的MAP,我们进行交叉验证。交叉验证的每次迭代都将用户分成训练和测试两组。测试组的听歌纪录还被进一步分成隐藏和可见的两组。模型由训练组和测试组中的可见隐形评分数据进行训练。之后,对测试组中隐藏组的MAP分数进行运算来判断推荐质量。为了提高效率,这里我们随机选择了100个用户。
为了确定模型的参数,我们对rank、λ、α分别都在一个一维网格上使用了一个5层的交叉验证。我们将结果与一个基线流行度模型(baseline popularity model)比较,后者只是简单地推荐用户没有听过的歌中最流行的那些歌曲。下图是结果:
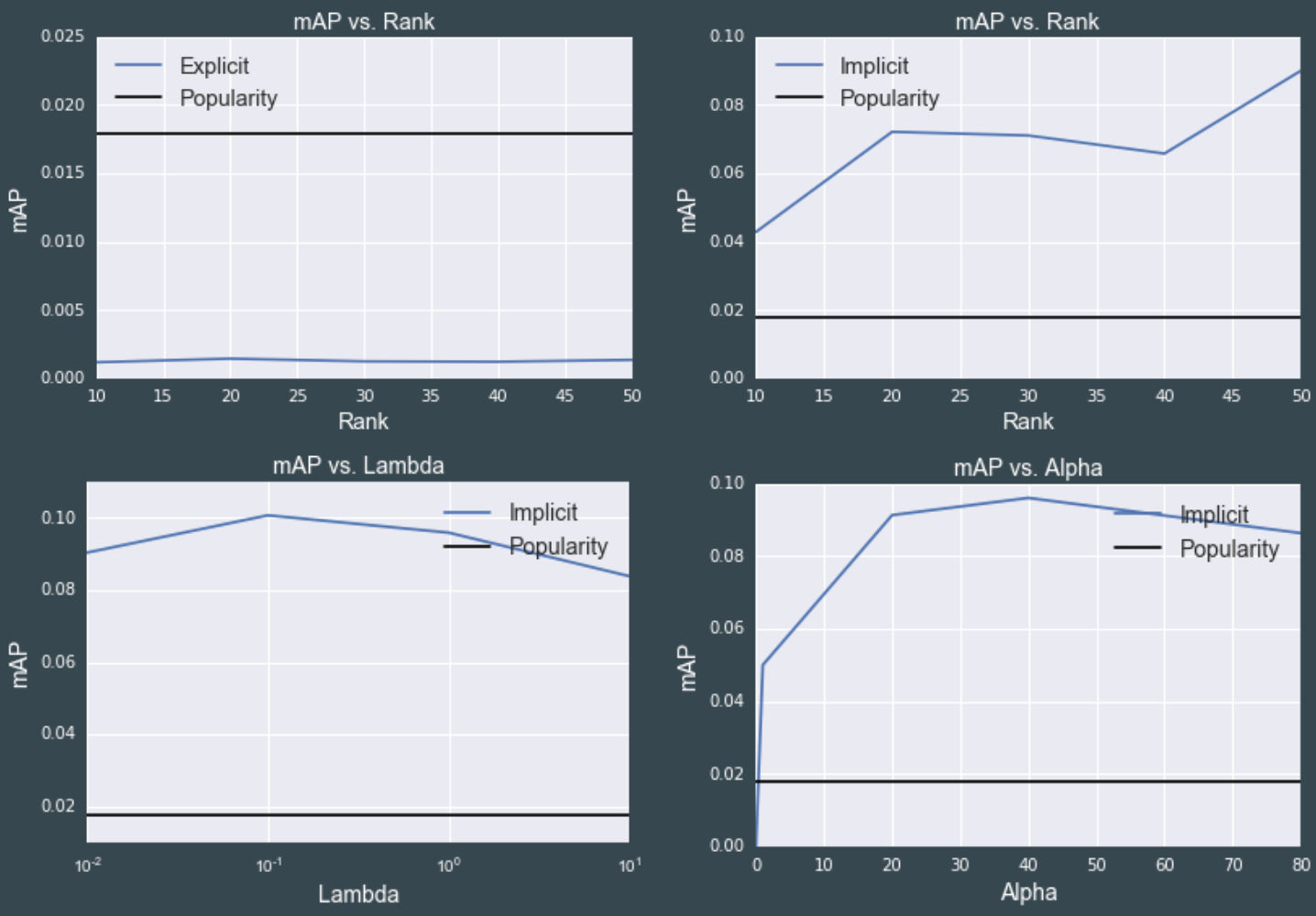
a图表中,我们首先跑了下显式模型,它的表现很差,这并不意外,因为本身数据并不够显性,这个模型并不适合。
b图显示了作为一个rank函数的隐式模型。总的来说,rank越高,表现越好。更高阶的矩阵可以提供更好的用户-物品互动。我们选择rank等于50,这是综合考虑准确度和运算效率后的最合适值。
从c图中,我们发现λ对模型的表现并无明显影响,而一旦λ太大,超过1,模型的质量就会下降。
相反,α对模型质量影响很大。我们找到它的最佳值为40,这也是这个算法的作者建议的数值。
所以,最价值为rank=50,λ=0.1、α=40,最终的MAP分数为0.1。
我们现在得到一个可以很好地对单个用户进行推荐的模型。下一步是对群组用户提供推荐服务。
一个方法是将所有个人推荐结果以一种聚合策略进行整合。那么,如何保证这个策略适用于小的群体、较大的群体(比如乘坐一辆小巴出行的场景),以及最重要的,适用于品味差别很大的群体?
为了描述这个系统如何运作, 我们从我们的数据集中选择了一些用户。假设下图的三个用户一起旅行,Orpheus知道他们各自的收听历史,并且为每个人都做出推荐。下图是推荐的歌曲对应的置信度的情况。越接近1越确定用户会喜欢这首歌。
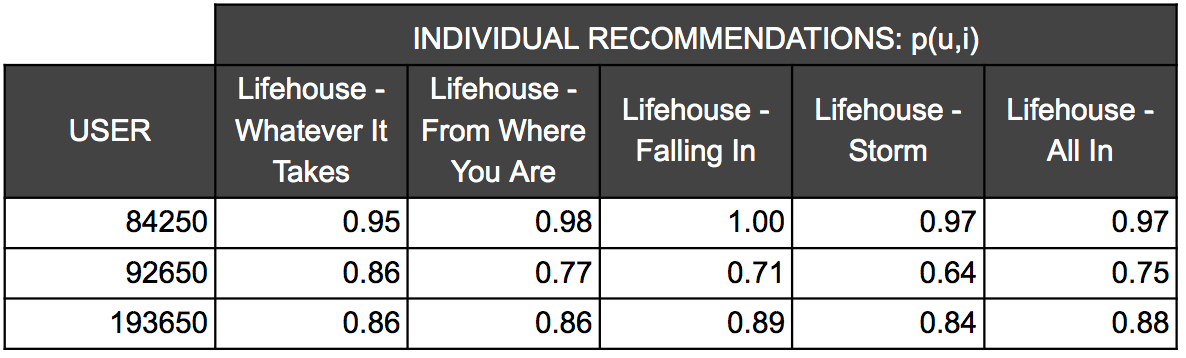
对于每首歌,我们选择最小的置信值作为所有用户的置信值。对此进行排序,得出下面的播放列表。

我们测试的其他的策略还有:平均策略,它试图让所有人都一样满足;最高兴策略,它考虑最能满足的用户的体验;乘法策略(multiplicative),它尝试得到所有人都满意的产品。
为了衡量每个用户对于歌单的满意度,我们使用下面的方程。这也可以得到整组对于一个歌单的整体满意度。
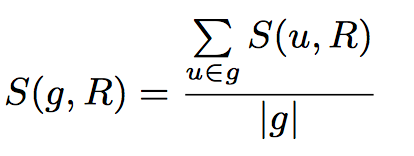
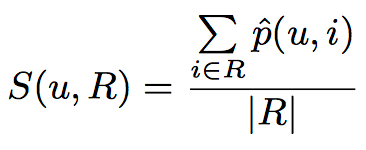
另一个需要考虑的变量是小组的同质化情况。k平均算法可以基于品味来识别每个用户和小组的相似度。这样我们可以组合出同质化的小组和异质化的小组。
然而最主要的挑战是数据组的维度和跨度不够。不过好在我们训练推荐模型时使用了缩减版的潜在因子矩阵,我们对用户的潜在特征进行k平均算法来得出分组。
为了测试我们的聚合策略,我们将我们的组分成两类:同质化和异质化小组。
每个组我们也分成3,5,7个人的不同人数构成,来看看规模的不同带来的影响。每个组20个样本,一共120个。
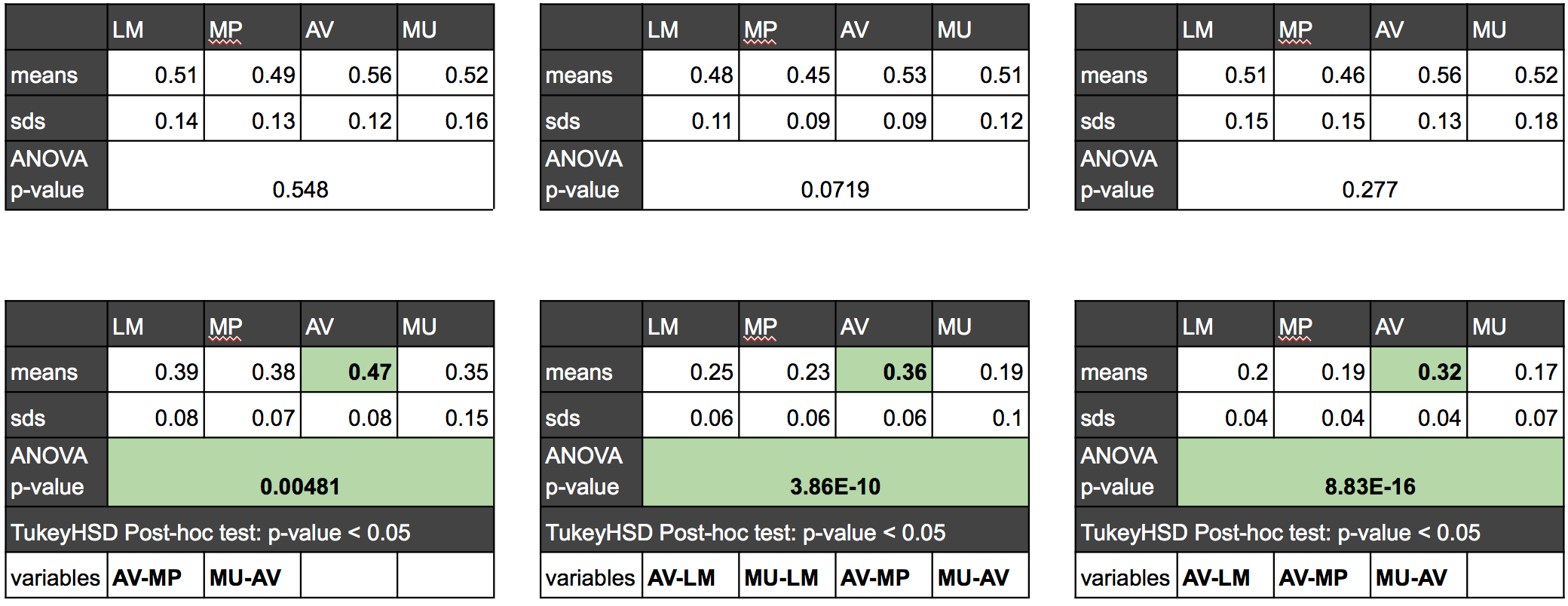
统计结果如下图所示。可以看出不同策略下,同质化小组的统计结果并没有什么区别。而对于异质化小组,平均策略是统计意义上表现更好的方法。如下图的ANOVA和Tukey HSD测试结果所示。
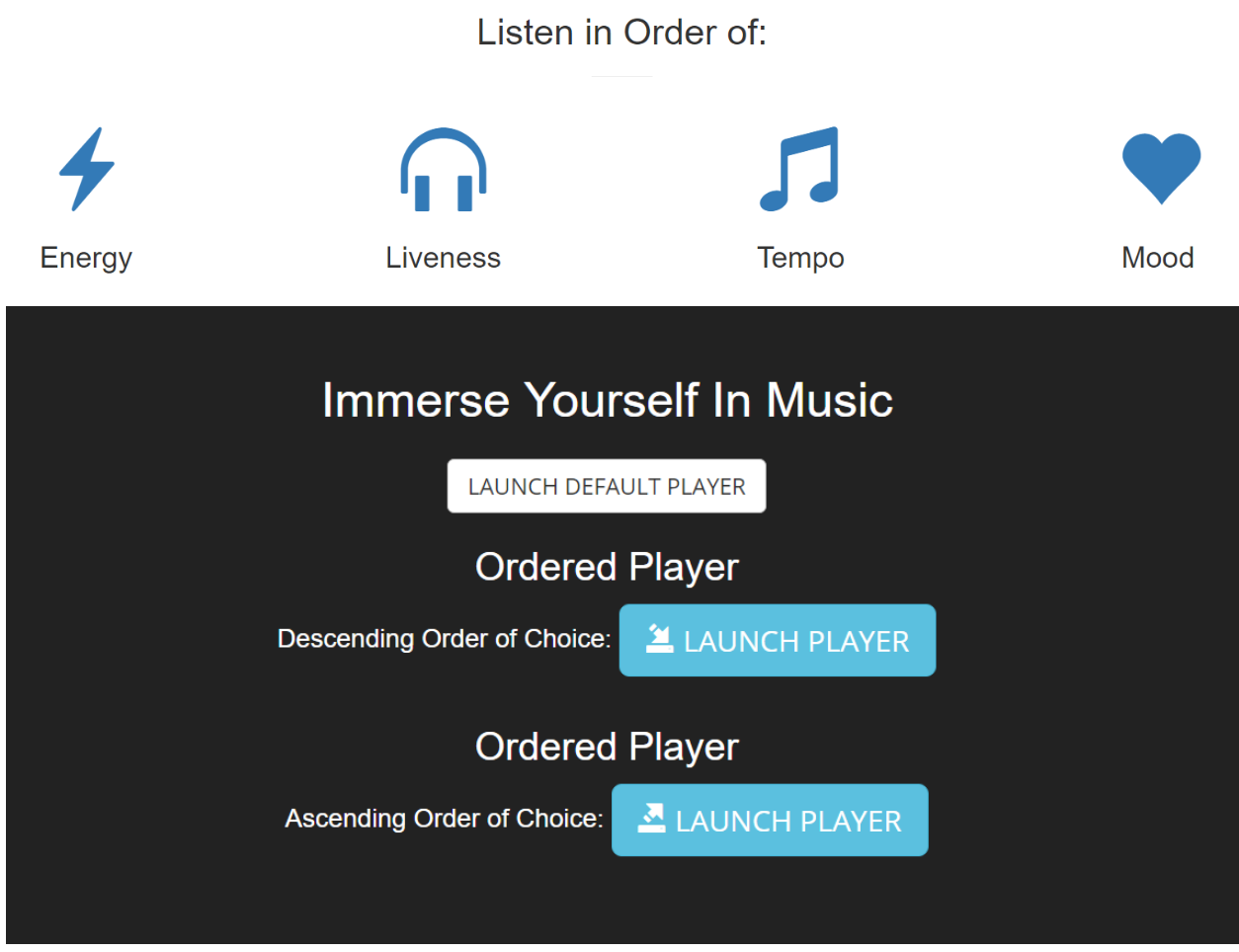
我们使用Flask设计了应用,它可以根据最多6人选择的偏好来从Spotify生成歌单。App内有内置播放器,可以播放歌单。用户也可以通过选择“能量”、“心情”等不同类型来得到推荐歌单。如下图所示。
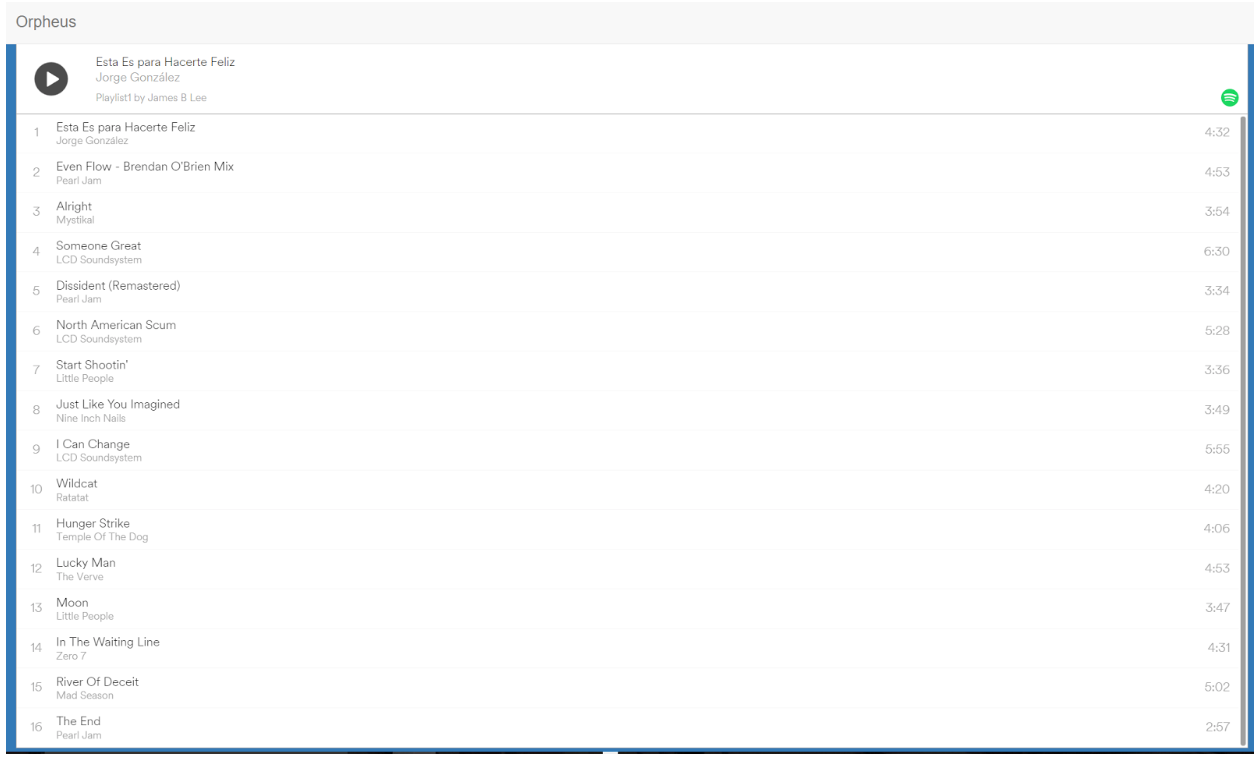
有了这个软件,你与朋友们的旅行一定充满了音乐的乐趣。
(本文编译自技术博客 Orpheus: A Multi-User Music Recommendation System,仅代作者观点)
Joshua Litven研究生毕业于英属哥伦比亚大学计算机专业,他在学习期间研究并行算法,之后还曾来到昆明教数学,闲时在当地酒吧表演摇滚乐。

James Lee毕业于纽约大学经济学专业,辅修数学。他的兴趣广泛,并最终合力推动他走向数据科学领域。

Oamar Gianan有15年的信息科学产业的经验,主要在云计算领域。在大数据相关的工作中对数据分析产生兴趣。他曾在菲律宾马尼拉长期从事云计算工作,之后搬到纽约。他的终极目标是建立一个机器学习模型来预测到底哪里是最拥挤的度假地。

DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing004并备注“数据社群”,合作请联系datahero@dtcj.com。

分享这篇文章到
2019-02-15

2019-01-17

2018-12-28

2018-12-07