
赚钱这事儿,如何放心交给机器打理?
2019-01-17

意见
反馈

回到
顶部

2018-04-18
当我们分析数据时,究竟要分析什么
康奈尔大学的研究表明,27%新餐厅会在第一年倒闭,而将近有60%的餐厅会在三年内倒闭。无法经营成功的一个关键性阻碍是Yelp曝光率不足。经营良好的餐厅,顾客会定期光临,会有较高评分和点评数量,这样会提高餐厅在搜索排名中的位置,为任何倒霉事保留缓冲空间。
Yelp中的餐厅排名是被全球公认的,它是利用大众经验和点评的最好例子之一。我们想要寻求的答案是——影响餐厅经营成功的关键特征是什么?我们相信从Yelp提供的与评分相关的官方数据中,一定能找出可识别的重要特征。
这些关键特征可以是商家经营的固有属性,例如开业时间,环境吵闹程度,也可以是客户的主观因素。通过数据可视化和预测模型,我们探索出在Yelp中取得高分的关键特征。我们通过基于隐狄利克雷分布(Latent Dirichlet Allocation)的主题模型算法处理客户评价内容。我们的最终作品,汇总了我们的各种发现,以R Shiny应用——YelpQuest的形式进行呈现。
我们的目标是:确定出能在Yelp中取得高评分的关键属性和特征。结合数据可视化和机器学习算法,识别出高商业评分的影响属性和特征。利用自然语言处理从用户评价中提炼出有价值的信息。喜欢奇思妙想的我们五个人,利用R Shiny 构建应用程序来帮助餐厅拥有者们通过以下三种方式进入餐饮市场:
地图:针对经营成功的餐厅进行地理位置分析
主题模型:针对不同类别的餐厅进行差评分析
菜系分类库 (Cuisine Gallery):对好评如潮的菜系种类进行分析
数据准备
我们应用的数据源来自于Yelp 2016 Dataset Challenge,它提供的数据表有:业务表(businesss),评价表(reviews),小贴士表(tips,更简短的评价),用户信息表(user information)和签到表(check-ins)。其中业务表(business table)中列出了餐厅的名称,地理位置,营业时间,菜系类别,平均星级评分,评价数量和其他与经营相关的一系列因素,如:吵闹程度,预订政策。评价表(review table)中列出餐厅星级评分,评价内容,评价时间,和该评价获得的支持率。我们限制采样数据集的范围在美国凤凰城(Phoenix)的大都市区域,然后通过类别过滤业务表(business)数据,仅保留餐厅和评价数据。从餐厅中获取到的评价文本会构成该项目的语料库。
关于预测,虽然只有9427家餐厅为样本,但特征的数量是十分庞大的。我们拥有的数据不足以充分支持结论。特征简化或者选择一个相对复杂的模型是有必要的。
对于不同菜系的餐厅,好评/差评 的标准是不同的。仅通过评价星级无法完全捕捉客户的观点。例如,快餐店的评分一般都很低;因此,4星评分的快餐店比4星评分的意大利餐厅更出色。

业务表(Business Table)
从业务表文件中查找出餐厅
创建只包括餐厅(restaurants)的业务子表文件
创建包括评价,签到、小贴士的子表文件
从评价,签到和小贴士子文件中进行数据总结(例如:每个餐厅的签到/小贴士/评价总数量),并创建包括业务ID和求和字段的概况数据文件,该文件可以追加到餐厅(restaurants)文件中
合并概况数据到业务餐厅(restaurants)数据中,并形成最终的模型数据集
评价表(Reviews Table)
根据餐厅分类得到平均分,判断各餐厅是高于还是低于平均分(例如,在分类平均值中,泰式:4.5星,快餐店:3.5星)
基于餐厅类别平均分,创建好评的数据子集
基于餐厅类别平均分,创建差评的数据子集
连接从步骤2到步骤3得到的两个子集
从步骤4创建顶级菜肴的评价子集,对好评和差评的数据集根据评价进行主题建模。
菜系比价格对星级的影响更大
通过探索性分析,我们首先想要检测自己那些先入为主的观点。当我们想到5星餐厅时,我们不会想到是快餐店或者披萨店。我们想到的是富丽堂皇的欧洲菜,如意大利菜或法国菜。通过菜系进行分类计算评分平均值,我们得到了以下的信息图表,例如:泰式或希腊菜系会有很高的评分,而自助餐,快餐和鸡翅店会有较低的评分。这些数据似乎能支持我们的假设:餐厅的评分跟特定的菜系类别有关。
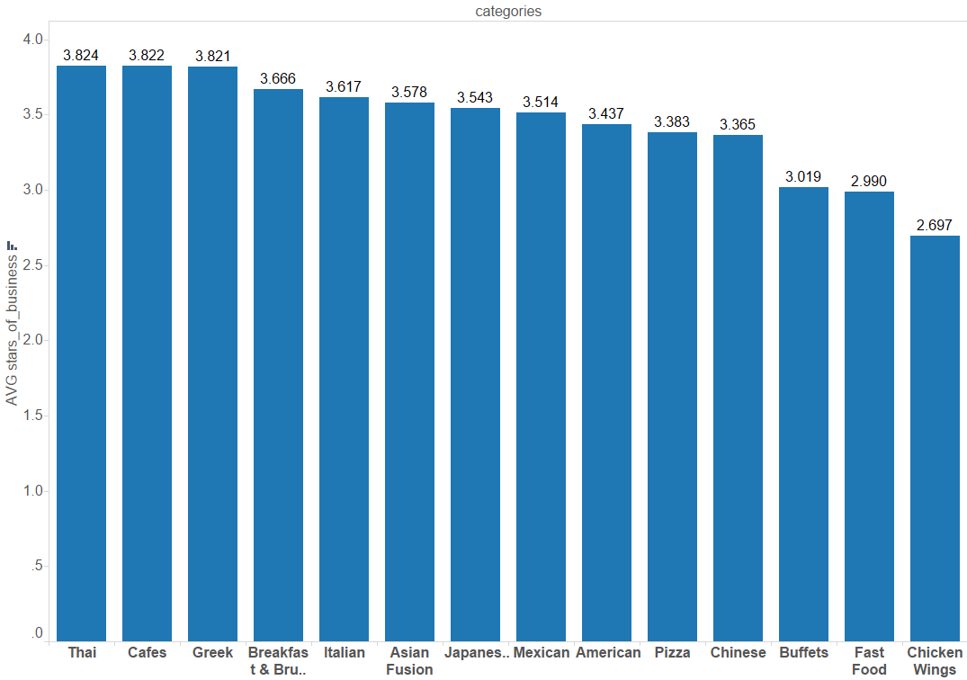
与此同时,当我们想象5星评分的餐厅时,一般不会想到路边的便宜小餐厅。为检测人均消费对餐厅评分的影响,我们绘制了以下Mosaic图。你看到的是关于价格范围和评分水平的卡方检验(它给出了一个很显著的P值 2.2e-16)。
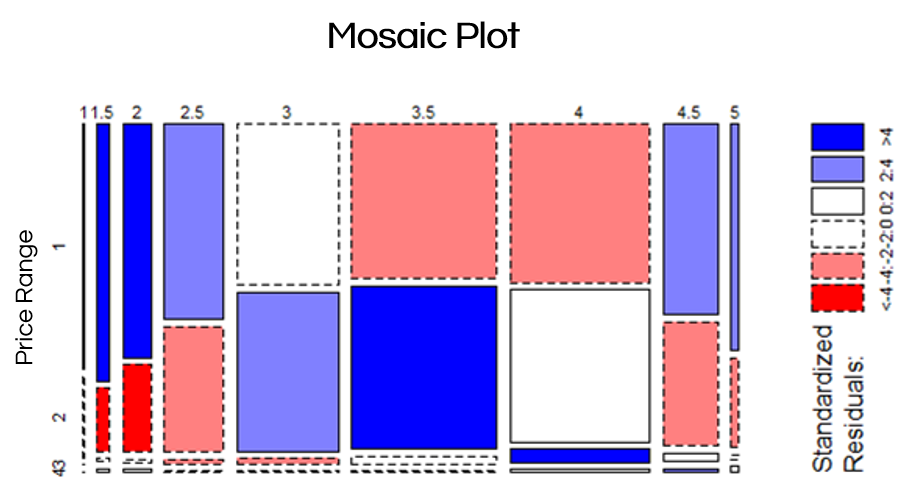
Mosaic图使用颜色作为比较各价格范围和星级评分组合下,观测值与期待值的差别(注:如图所示,横向为星级评分,分为9组,纵向为价格范围,分为4组。如果价格范围对星级评分没有影响,则各价格段的星级评分频率分布是均一的,即期待值,应显示为白色,而本例中多处显示为红色或蓝色,表示价格范围对星级评分有影响)。蓝颜色表示,相对于预期结果,实际上有更多的观测值,而红色却有更少的观测值。在本案例中,我们可以观察到,价格和星级评分不是完全独立的,该结果可通过χ2检测得到证实。
位置、人数、消费才是重中之重
为从数据中确定出关键的影响特征,我们决定使用基于树的模型。
相对于观察到的大量属性和特征,我们的数据表显得很稀疏。基于树的模型可以解决稀疏性问题,特别是XGBoost更为出色。我们选择了三种不同的模型:随机森林,XgBoost和梯度增强树。下图展示了基于XGBoost的结果,因为它具有更高的稳定性。
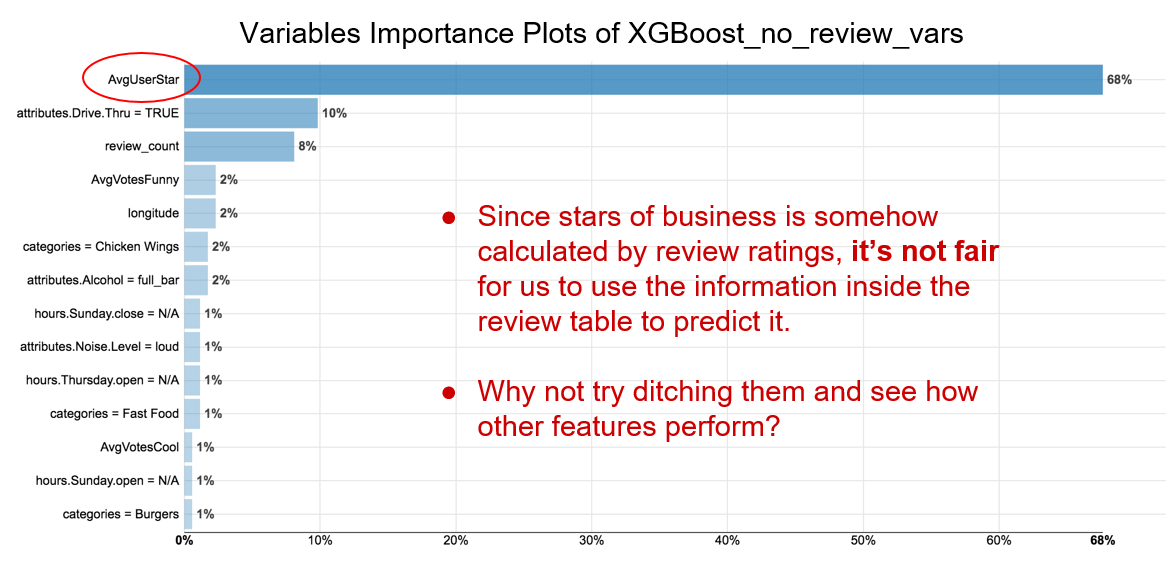
首先我们将所有的有效属性作为预测因子进行建模,拟合到了一个R square =0.936的模型。根据特征重要性的图示我们可以得出一个很强的影响因子——用户平均评价星级。然而,该信息并不是什么远见卓识;总体的商业评分是所有用户评分的平均值,因此显而易见该因素在图表中会很显著。我们决定移除所有跟评价相关的因素后,再重新运行XGBoost:
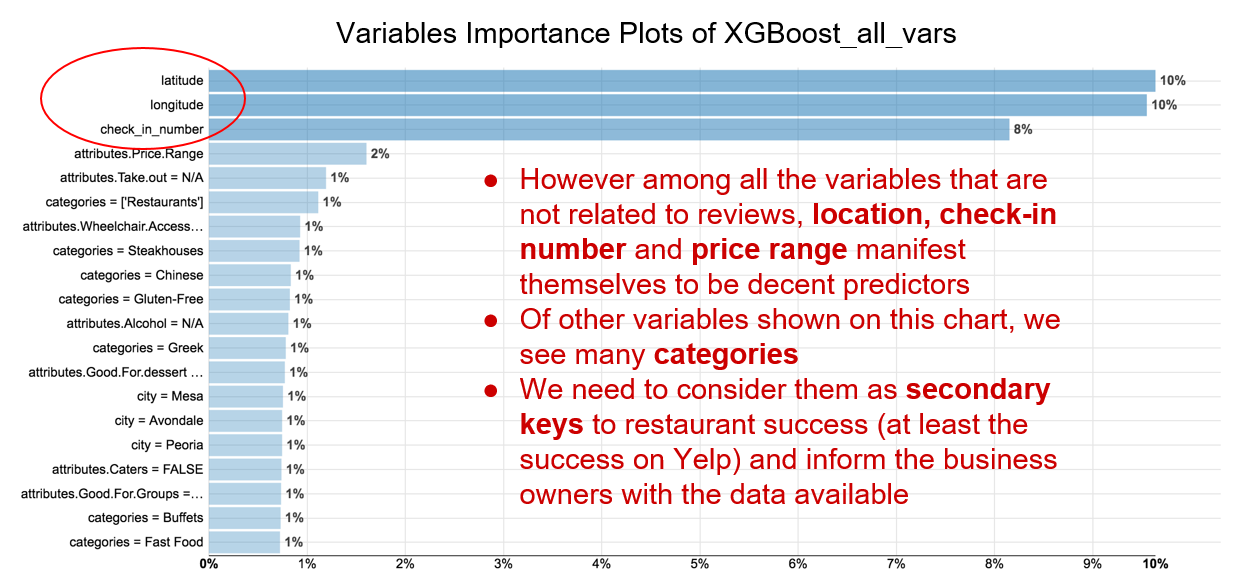
第二次运行时,R square 明显地下降到0.318,去除评价相关的因素后,我们无法很好的进行评分预测。这次试验中,地理位置,用餐人数,人均消费是重要的预测因子。
利用点评文本数据建立模型
在建立模型前,我们需要对文本进行一些预处理。
比如删除常用的停用词、标点符号、完成字母转换等,然后把文本分词为二元词和三元词(n-gram语言模型中的bigrams和trigrams)。
由于一些词汇与其他词汇连用时会改变其原有的意思,我们决定将点评文本分词为二元词组和三元词组(2或3字的组合) 。例如,如果将 “不好” 分成 “不” 和 “好” 两个单词,那么分析过程就会出错。
为了理解点评数据中的关键主题,我们使用LDA主题建模算法来提取每个类别和每个评级中的20项关键主题。我们使用R语言扩展包 “LDAvis” 来进行交互式主题模型的可视化, 并且回答了这些问题:
每项关键主题都是什么意思?
这些关键主题普遍性怎么样?
这些关键主题是如何相互关联?
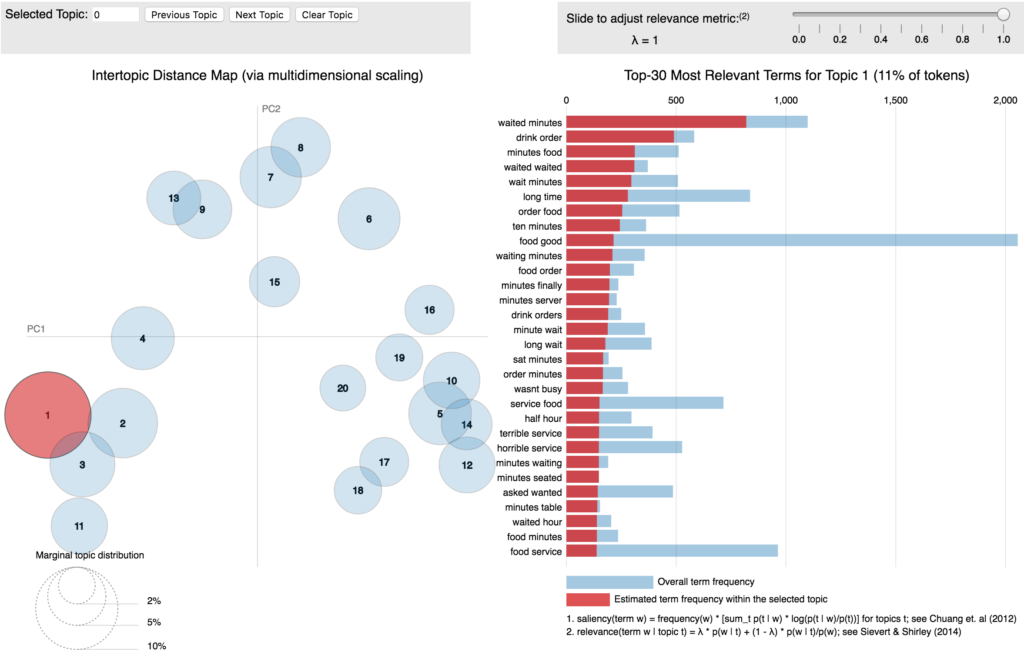
上图右侧结果是LDAvis对第一个问题的回答。在右侧的条形图中,y轴是词条,x轴是出现次数,你可以看出点评内容中特定词条在各主题内的出现次数。我们采用一种特殊的度量标准——显著性(saliency)——来确定一项主题中最重要的词条。显著性就是词条在单个主题中出现频率相对其在整个点评文本中出现频率的比例。排列越靠前的词条也就越独特,相对于这项主题也就更重要。
上图左侧LDAvis的结果图叫做主题间距模型。它为主题模型提供全局视图,并且回答了后两个问题——每个主题圆的直径代表每项主题的普遍性;詹森 - 香农离散度计算出主题间的相互距离,(詹森 - 香农离散度是测算两个概率分布间相似性的流行方法),然后再按比例调整每两个主题的间距。要点在于,两个气泡越是靠近彼此,它们就越相似。一图胜千言,因此我们将它纳入了我们的应用程序。
为餐饮企业主制作一个推荐小程序
我们的最终产品为R Shiny应用程序,包含以下几项功能:
地图:餐厅成功的地理位置分析
主题建模:理解指定类别市场中的差评
料理画廊:理解好评中频繁出现的料理主题
我们的主要用户将是想要开餐厅或扩展餐厅的小企业主。
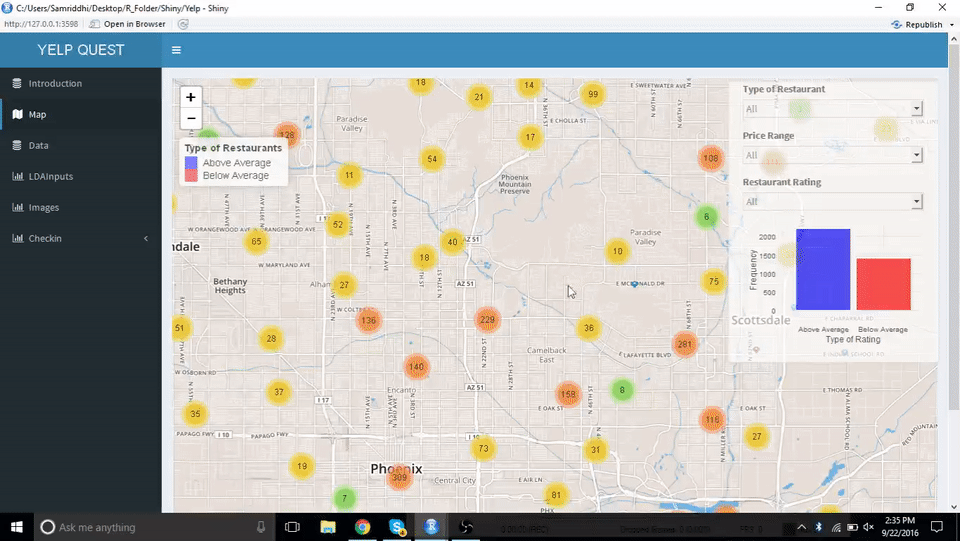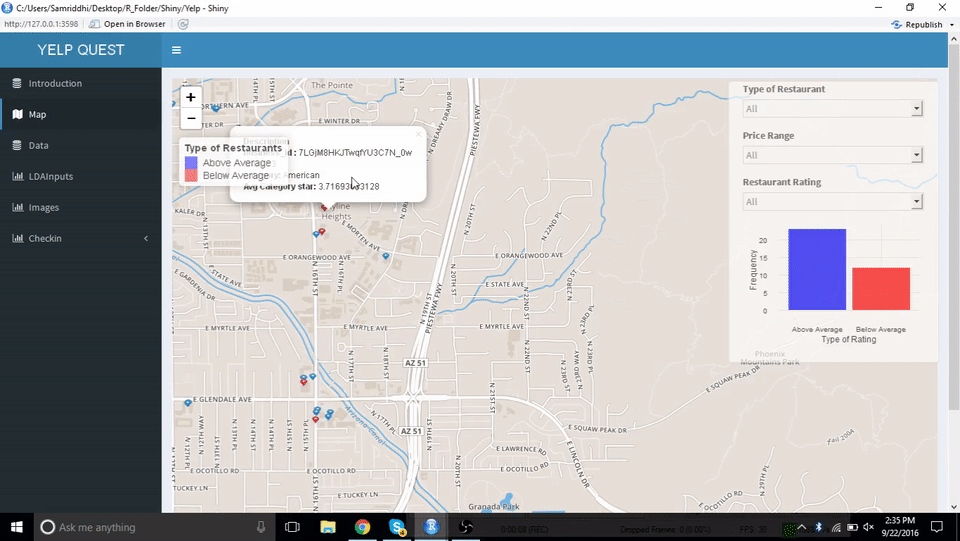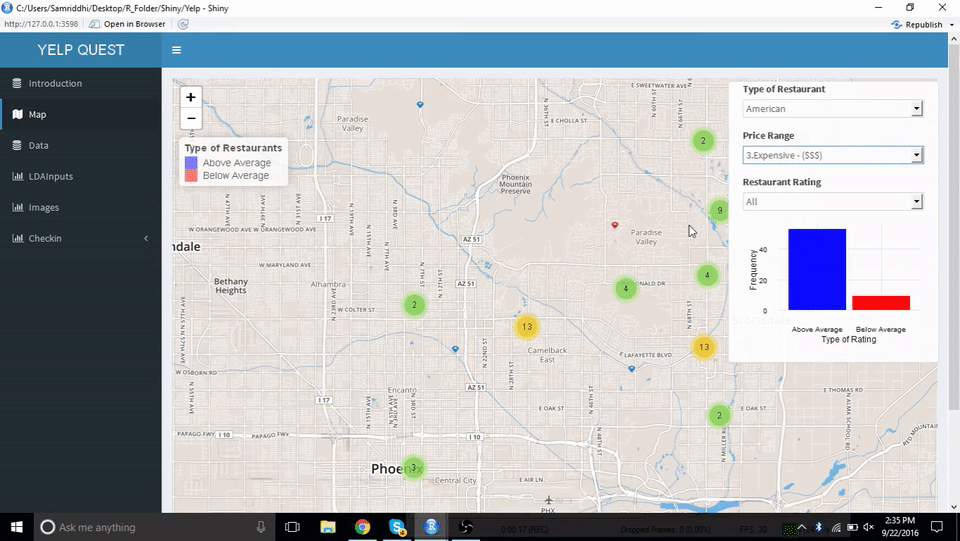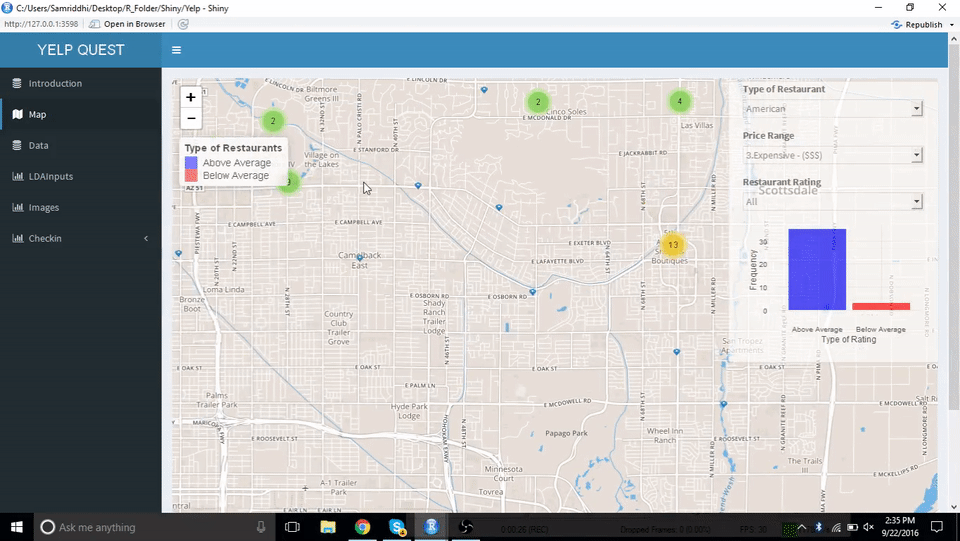
通过地图,用户可以找出开餐厅最好的地方,或是鸟瞰餐厅间的竞争状况。亚利桑那州的一张互动地图显示出了这些餐厅,它们被分为某类餐厅中 “高于同类平均水平” 和 “低于同类平均水平” 两组。用户通过点击地图上的标记就能获得有关餐馆的具体信息。现在假设用户希望开一家意大利餐厅,在地图上,人们普遍喜欢意大利食品的最大片区就很可能是开餐厅的好地点。
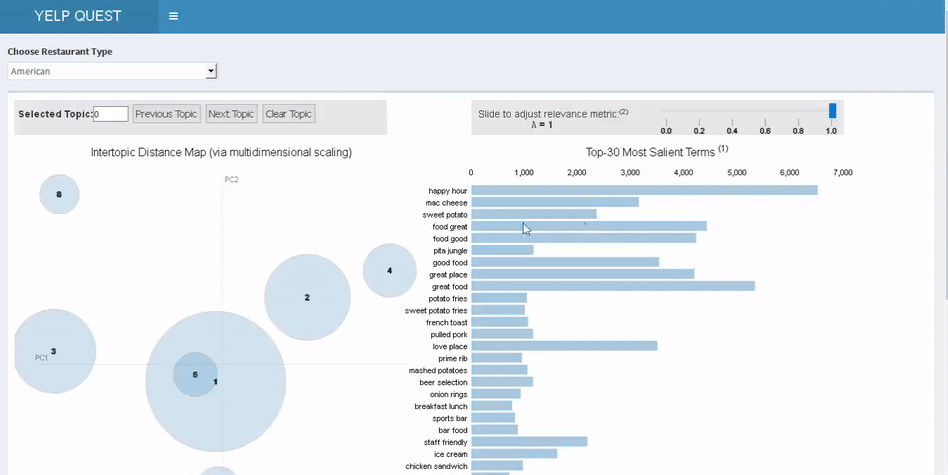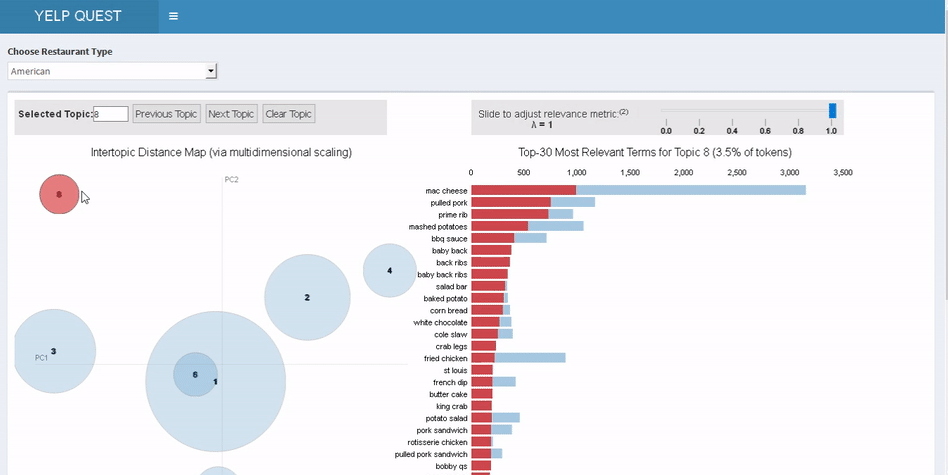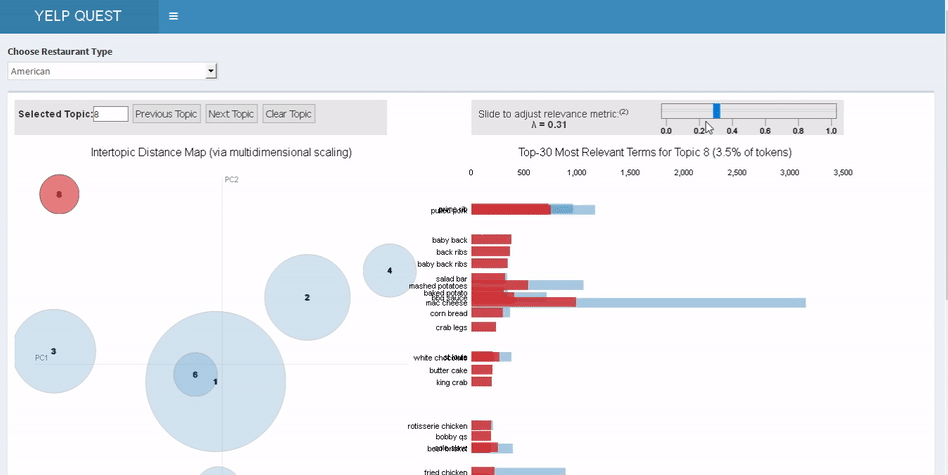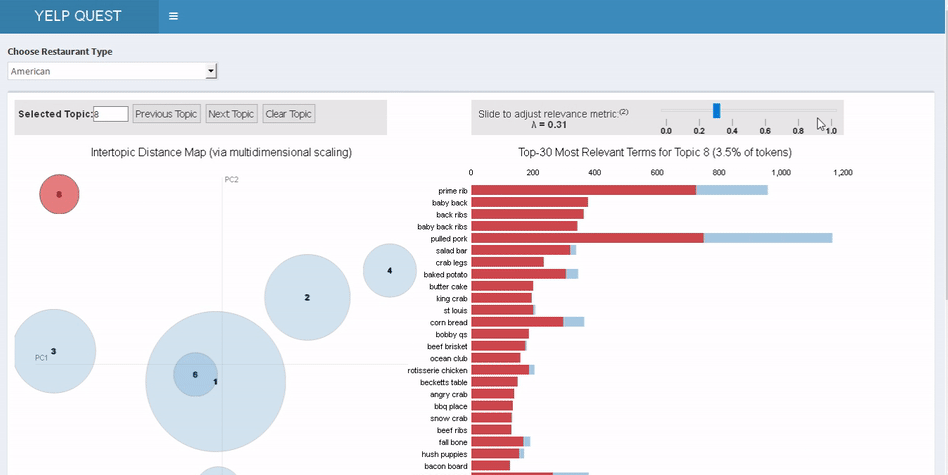
以前如果想要了解其他餐馆的负面点评,唯一方法就是阅读每一页点评。而主题模型是迅速汇总信息的最快方式。用户可以快速探索不同的主题气泡,并基于点评中词条的出现频率找出问题。例如,如果时间是一个很重要的问题,那么在筹开餐厅时就可以利用这一点。
菜单库可以显示出最受好评的菜名。餐厅可以通过了解最流行的词条来建立自己餐厅的菜单。
通过使用预测模型和探索式数据分析(EDA),我们确定了要纳入应用程序YelpQuest中作为预测因子和过滤器的关键特征。而基于差评和好评的主题模型使我们的产品有望帮助未来的小型企业拥有者的成长和成功。
(本文编译自纽约数据科学院技术博客 YelpQuest--Begin your journey here,仅代表作者观点。)
数据侠门派
Charles Leung,卡内基 · 梅隆大学化学工程学士,EVRAZ 质量工程师、 工艺工程师、 环境工程师。感兴趣的研究方向是应用大数据解决质量和生产问题,以及创建自动化和优化炼钢过程工具。

Jiaxu Luo,哥伦比亚大学化学工程硕士。相信数据驱动的IT技术,尤其是蓬勃发展的云计算,机器学习,物联网,将以空前的速度和方式重新定义各产业。

Danli,纽约大学市场分析硕士。具有5年的市场营销和媒体从业经验,从事综合的媒介策划和快速消费品行业的ROMI分析。

Samriddhi Shakya,奥本大学地理学硕士,擅长GIS,曾参与美国阿拉巴马州环境保护署 (EPA) 和水资源办公室 (OWR)项目。

关于DT×NYCDSA
DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

加入数据侠
数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing004并备注“数据社群”,合作请联系datahero@dtcj.com。

分享这篇文章到
2019-01-17

2019-02-15

2018-12-29
2018-12-11