
人工智能如何助力企业突围互联网运营困局?
2019-02-15

意见
反馈

回到
顶部

Stefan,Yvonne&Daniel 2018-04-23
如今,面对海量的娱乐信息,喜欢追剧、玩儿游戏的你是不是有时候也对这些感到力不从心呢?很多时候,我们要浏览很多第三方评价信息,花很多时间才能决定要不要追一个剧或者试玩儿一个游戏。
不过,也有一些网站试图帮我们简化这个筛选流程,比如metacritic.com。它们尝试通过综合各种评论来为用户简化挑选过程,但依然存在一些问题:
产品推荐明显与作品名称直接挂钩(比如你喜欢超级玛丽,你就会被其他马里奥系列游戏的推荐信息淹没)
用户界面充斥着过多的次要及不必要的信息
评论的内容有时候与最终给出的评分并不一致
我们尝试对以上问题作出改进。
Metarecommendr是我们自己设计的一款拥有直观流畅的用户界面的应用,它使用内容过滤和协同过滤技术来为你作出最佳推荐。它的工作流程如下:
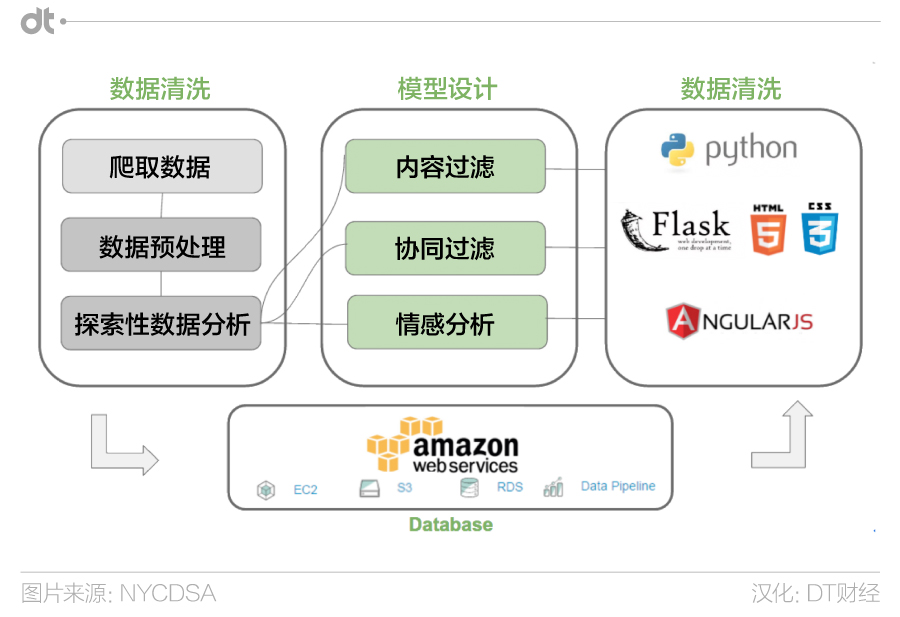
我们使用python的scrapy爬取所有需要的数据,共使用12个爬虫,爬取了每个项目列表,每个具体项目的简介和细节,每个项目的专业评论和用户评论。其中最长的一个爬虫耗时10天才完成数据收集。
我们预料到会得到巨量数据,因此决定直接将数据爬取到一个数据库而非文本文件。我们在SQlite搭建了初级版本的数据库,这仅用了我们几分钟时间。爬取完成后,我们将数据输出至一个运行在AWS RDS服务器上的MySQL数据库。为了避免将584 mb的数据从本地主机传至远程数据库,我们将所有数据上传到AWS S3并且使用了一个AWS data pipeline来通过AWS EC2直接将数据从S3转至RDS。这样操作大大降低了数据转移时间。
我们选择同时使用内容和协同过滤来进行推荐,其中一个原因就是我们在数据库的评分数据分布上发现了问题。我们总共有大约100万个评分数据,一半来自专业评论家,一半来自用户,而这两组数据都呈现负偏态分布(negatively skewed),由于大多数产品的评价都偏正面,因此若在协同过滤时单纯依赖评分将无法提供足够的颗粒度。
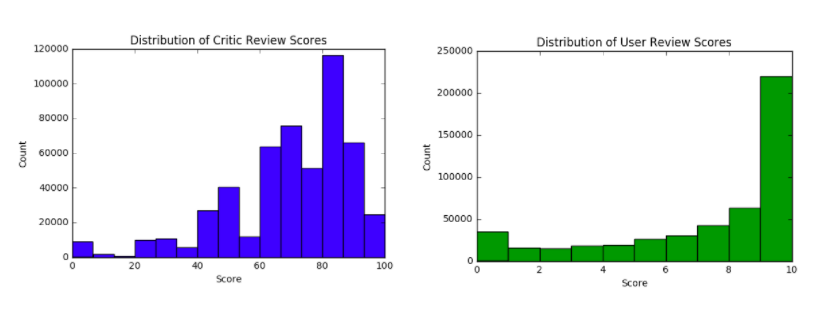
(图片说明:左-专家评分分布;右-用户评分分布)
从metacritic.com上爬取的数据包括:20416款游戏,5470部电影,1978部电视节目以及998582份评论文章。
一个有趣的发现是,一个作品对应的评论文章的数量多寡并不一定能代表作品的质量。比如游戏《僵尸末世录(Infestation: Survivor Stories)》有最多的评论,但评分却低得可怜。这给我们一个直观感受:评分很高或很低的游戏都会引发大量讨论。

推荐算法最主要包括两类:基于内容过滤和协同过滤。
基于内容过滤:基于一个产品的元数据进行推荐,经典例子是音乐软件Pandora。
协同过滤:这种算法将用户的行为和与作品的互动考虑进内,它可以再进一步分为两类:
基于用户的协同过滤:会基于与你类似的用户的行为做出推荐,典型案例是Spotify。
基于物品的协同过滤:根据一个基于用户评分数据设计的物品-物品相似度衡量标准做出推荐。典型例子是亚马逊。
我们首先看基于内容的过滤。
由于数据集的很大一部分是文字数据,因此我们选择Doc2Vec作为基于内容的推荐中特征工程的操作方式。这是一种无监督学习算法,用于从文档中提出向量。它是Word2Vec的一项扩展。Doc2Vec可以学习不同单词间的语意相似度,这使它比tf-idf更加复杂。我们对专业评论文章的一个研究模型的产出显示,它对单词“excellent”的近义词的识别成果令人满意。

我们的项目中,两个Doc2Vec模型分别使用简介(summary)和专业评论文章的数据进行训练。我们选择不使用用户评论进行训练,因为其中没有足够多的描述性词语可以用来产生有意义的推荐。在用户界面方面,用户选择他们喜欢的产品,之后会根据余弦相似性推荐其他产品。越接近1,两个产品越相似。
其次是协同过滤。

在这个项目中,对数据集进行协同过滤所遇到的困难是,这个用户-物品矩阵较高的维度以及稀疏度。一共有27400个产品以及63000个用户,而每个用户的平均评论数则是少于3 。为了减少高维度,我们使用了截断特征值分解(Truncated SVD)。具体过程我们就不多加赘述,总的来说就是:用户对几个物品做出打分并输入,之后由SVD生成一个用户-物品矩阵,并对其进行解析。对于一个给定用户i,这种方法允许我们得到他对不同物品的预测打分,并且根据其中打分最高项做出推荐。
另外,为了更好理解物品的评价得分,我们使用一个改良版的皮尔森相关系数函数对各个物品彼此进行比较。为了进一步简化,若彼此的重合评论少于3个,我们给它的r值为0,或者说是没有相关性。
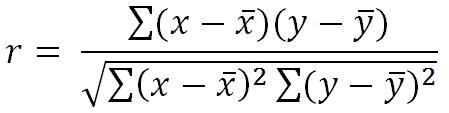
物品-物品矩阵的方法也ringworm可以做跨类别的推荐,因为这个算法不再局限于物品的元数据(像协同过滤那样)。用户界面方面,他们选择自己喜欢的作品,之后就会被推荐与之相关性最高的作品。
如我们开头提到的,用户评论打分对应的情感与评论的文本数据并不一定一致。因此,我们仅对专业评论进行情感分析。积极和消极分别被定义为:评论打分小于或等于55的定为消极,85及以上为积极,在这之间的打分不做分析。
情感分析使用doc2vec提取的词向量作为特征。我们尝试了不同的机器学习模型,包括逻辑回归、朴素贝叶斯、SVM和不同的神经网络。不同的模型的准确度表现如下:
逻辑回归:75%
SVM:约65%
朴素贝叶斯:约65%
长短期记忆递归神经网络(LTSM RNN):约75%
卷积神经网络(CNN):约88%
最终,最佳模型为加入了一些RNN元素的CNN模型。它有2个卷基层和池化层,2个递归神经LTSM层,和3个紧密的全连接的层(fully connected layers)。
这个模型的精度超过90%。
在应用中,这个情感分析以互动形式实现。用户键入评论,模型对文字进行评估,之后给用户提出反馈,告诉用户其评分是否符合其输入的评论内容。我们能希望继续这块的研究来提高精度,并作为推荐系统的另一个预处理步骤。
不过,这套系统也不是完美的,未来可以改进的地方有:
制作一个融合基于内容过滤和协同过滤的混合推荐系统
增加更多筛选选项,实现更加定制化的用户体验
使用NLP扩展情感分析模型,以得到更好的评分预测
(本文编译自技术博客 Metarecommendr: A recommendation system for video games, movies and TV shows,仅代表作者观点。)
Stefan Heinz本科毕业于德国海尔布隆大学逻辑学专业,研究生在荷兰马斯特里赫特大学攻读信息管理专业。与大量数据打交道的工作让他感兴趣,他精通SQL,VB和PHP等。

Yvonne Lau本科修读经济学和数学,研究生就读于耶鲁大学。在一家NGO担任数据分析师时,她对数据科学产生兴趣,感受到数据处理的能力和趣味。她希望使用分析和数据可视化能力来解决商业及日常问题。

Daniel Epstein博士毕业于犹他大学神经系统科学专业。在对行为及神经图像数据进行分析时对利用数据科学分析人类行为以及消费趋势等产生兴趣。

DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing004并备注“数据社群”,合作请联系datahero@dtcj.com。

(了解更多有趣又有料的商业数据分析,欢迎关注DT财经微信公众号“DTcaijing”,下载“DT·一财”APP)
分享这篇文章到
2019-02-15

2018-12-07

2018-12-29

2019-01-08